MEERKAT: Audio-Visual Large Language Model for Grounding in Space and Time (ECCV 2024)
Abstract
LLM(Large Language Model)의 뛰어난 능력을 활용해서 최근의 MLLM(Multimodal Large Language Model) 연구는 이를 visual, audio와 같은 다른 modality로 확장하고 있다. 그러나 이러한 방향의 발전은 대체로 audio-visual semantics를 coarse한 수준으로 이해하면 되는 task에 초점을 맞춰왔다. 해당 논문에서는 image와 audio를 공간적(spatially)/시간적(temporally)으로 fine하게 이해하는 audio-visual LLM인 MEEAKAT을 제시한다. (MEERKAT, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally)
Optimal transport에 기반한 새로운 modality alignment module과 audio-visual 일관성을 강제하는 cross-attention module을 통해서 audio reffered image grounding, image guided audio temporal localization, audio-visual fact checking과 같은 도전적인 task를 해결할 수 있다.
'AVFIT' dataset을 구축하고, MEEARKATBENCH를 소개한다.
Introduction

- Audio Referred Image Grounding (왼쪽)
audio와 함께 Image가 주어졌을 때, 해당 소리가 나는 물체를 찾고 bounding box로 정확한 위치 표시
- Audio-Visual Fact-checking / IG Audio Temporal Localization (중앙)
audio에서 특정 소리가 언제 나는지 구간을 찾아냄. image와 visual 간 내용의 consistency를 검증하여 사실 여부를 판단함
- AV Captioning / AV Question Answering (오른쪽)
audio+image를 함께 보고 question에 답함. audio+image 정보를 사용해서 장면을 문장으로 기술하는 task (captioning)

Meerkat은 공간.시간 grounding을 동시에 지원하고, end-to-end로 학습되며, 가장 포괄적인 프레임워크임을 보여주는 표이다.
LLMs는 다양한 NLP task에서 뛰어난 성능을 보여 왔으며, 이해 및 추론 능력에서 인간 수준의 정확도에 도달했다. 더 나아가 다른 modality 특히 vision과 결합될 수도 있다. audio는 관련된 시각 장면을 보완하는 경우가 많지만, LLM의 맥락에서는 상당 부분 미개척 영역으로 남아있다. 청취 능력을 갖춘 multimodal LLMs를 구축하면 새로운 응용을 가능하게 할 수 있다.
Table 1을 보면, 선행 연구들은 MLLMs에 audio를 도입했지만, 대부분이 captioning과 question-answering과 같은 coarse-grained task에 초점을 맞추었다.
저자들의 목표는 LLM의 힘을 fine-grained audio-visual understanding에 활용하는 것이다. 하지만 다음과 같은 이유로 어렵다.
1. 서로 다른 task 간 input&output 형식의 불일치가 존재한다.
2. grounding 능력을 갖춘 audio-visual LLM을 학습하기 위한 대규모 dataset이 존재하지 않는다.
기존 LLMs는 coarse-grained task로 제한되어 있으며, fine-grained의 이해 및 추론 능력을 달성하는 데 핵심 구성 요소인 cross-modality fusion을 포함하지 않는다.
이런 challenge를 해결하기 위해 MEERKAT을 제안한다.
MEERKAT은 image와 audio에서 각각 공간적 및 시간적으로 효과넉으로 grounding할 수 있는 최초의 통합 audio-visual LLM framework이다. 이 model은 fine-grained 이해 능력에 핵심적인 두 가지 module을 갖춘다.
- Modality alignment module: Optimal transport에 기반하여 weakly-supervised 방식으로 image와 audio patch 간의 cross-modal alignment을 학습
- Corss-modal attention module: Cross attention heatmap에서 일관성(consistency)을 강제할 수 있는 모듈
이 두 module을 결합하면 더 나은 joint audio-visual representation을 학습할 수 있으며, 이는 이후 downstream task를 향상시킨다.

Meerkat을 뒷받침하기 위해, 다섯 가지 서로 다른 audio-visual task를 통합한 MeerkatBench
다섯 task의 학습을 가능하게 하기 위해, fine-grained audio-visual segmantic을 학습하는 데 난이도가 다양한 300만 개의 instruction tuning sample을 포함하는 대규모 dataset AVFIT도 큐레이션한다.
Contribution
- image와 audio에서 grounding할 수 있는 fine-grained spatio-temporal understanding 능력을 갖춘 audio-visual LLM인 MEERKAT을 제안한다.
- 다섯 가지 audio-visual learning task를 통합한 MeerkatBench와 fine-grained audio-visual semantic learning을 가능하게 하는 새로운 대규모 instruction tuning dataset AVFIT을 소개한다.
- 다섯 개의 benchmark task에서 평가한 결과, 모두에서 SOTA달성
Methodology

Multi-modal Feature Extraction
<image encoder>
batch 크기 k의 input image가 주어졌을 때, pretrained CLIP-ViT-B/16 encoder를 사용하여 image embedding을 추출한다.
<audio encoder>
raw audio input을 audio embedding으로 변환한다. CLAP audio transformer backbone을 audio encoder로 사용한다. 이 pretrained encoder를 활용하여 의미 있는 audio representation을 추출한다.
<LLM>
MEERKAT은 open sourced Llama 2-Chat(7B) large language model backbone으로 채택했다. pretrained LLM의 tokenizer는 text sequence T를 embedding으로 투영한다. image와 audio embedding을 LLM에 전달하기 전에, 서로 다른 modality 간 embedding 차원이 맞도록 추가 선형 계층을 통해 변환한다. (projection) LLM이 audio-visual input을 위한 통합 interface 역할을 하므로, 개별 task를 수행하기 위해 language token에 의존한다.
Audio-Visual Feature Alignment
<Audio-Visual Optimal Transport Alignment Module (AVOpT)>
Optimal Transport(OT) 방법을 포함하는 Earth Mover Distance based Algorithm은 최근 seamese network에서 query와 support image간 patch-level alignment에 활용되었다. 더 나아가 vision-language model에서, OT based algorithm은 patch-word alignment에도 사용되었다.
image(CLIP)와 audio(CLAP) encoder가 분리되어 학습되었기 때문에, 학습된 embedding은 서로 다른 의미 공간에 존재한다. 이런 patch-level alignment가 vision과 audio의 의미적 일관성을 향상시킬 수 있다. 이 pacth-level weak guidance가 global supervision보다 우수함을 실험적으로 보였다. (appendix)
주어진 image I와 audion A pair로부터 pacth-level (local) feature embedding을 각각 얻는다. 이러한 feature representation의 고유한 풍부한 의미 구조를 활용하여 cross-modal relation를 modeling하기 위해, image와 audio 각각에 대해 두 개의 이산 분포(discrete distributions)를 생성한다. 이 두 분포를 매칭하는 동안 최적 운송 계획을 식별한다.Cross domain alignment 과정에서 topological information (위상 정보)을 보존하면서 두 확률 분포 사이의 Wasserstein 거리 (WD)를 계산한다.
<Audio-Visual Attention Consistency Enforcement Module (AVACE)>
Cross-modal interaction은 audio와 visual modality를 정렬하는 데 필수적이다. 더불어서 region-level supervision은 효율적인 위치 추정을 장려할 수 있다. 최근 방법들의 성공에서 영감을 받아, 효율적인 음원 위치 지정을 위해 adapter-based cross-attention strategy를 사용한다. AVOpT의 modality 특화 feature는 대안 modality의 정보 인지(awareness)가 부족하며, 이는 cross-modal attention을 통해 주입될 수 있다. 따라서 audio-visual cross-modal reciprocity(상호 상태)를 가능하게 하기 위해 AVACE modeule을 제안한다.
(내가 주목할 부분)
Multimodal에서 Cross-attention 방식의 feature fusion은 image 내 관련 객체에 주의를 기울이는 데 효과적이지만, 배경 객체를 포함해 주목된 영역이 image 전반에 분산되는 등 불일치가 발생할 수 있다. 그 이유는 feature embedding 간 interaction의 질에 기인할 수 있다.
예시로, CLAP audio encoder가 바이올린 audio와 짝지어진 '바이올린을 연주하는 남자'와 같은 예시로 pretrain 되었다면, audio representation의 cross-modal knowledge는 image에서 남자와 바이올린 모두에 초첨을 맞추도록 유도한다. 따라서 더 우수한 영역 수준 alignment를 보장하기 위해, 관심 객체의 GT bounding box로 표시되는 경계 내로 cross-modality attention map을 한정한다.
Bounding box 이외의 범위는 1로, 그 이외의 범위는 0으로 masking한다. 이 bounding box 내부의 attention을 최대화하고, 그 외부는 최소화한다.
Loss로 사용
관심 있는 객체의 부분을 1로 masking, 이외의 부분은 0으로 masking (이진 마스크) 처리.
Box 내부 평균 attention을 크게, 외부 평균을 작게 만들어야함.
Box 내부 평균 attention 크게 → '1 - (평균)' 최소화
Box 외부 평균 attentino 작게 → '평균'을 최소화
Overall training objective
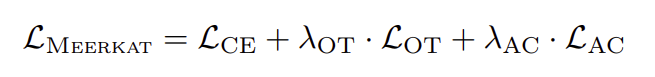
cross-entropy loss + weak AV alignment loss + attention consistency loss
Numerical Representation of Box Location and Time Segment Representation of Box Location
<Representation of Box Location>
Natural language sequence 내에 수치 값을 사용하여 bounding box 위치를 embedding한다. box는 직관적으로 좌상단과 우하단 모서리로 표현된다. 이 값들은 정규화되며, 정규화 계수는 해당 bounding box가 속한 image size에 의해 결정되다. 이러한 좌표는 task에 따라 input sequence or output sequence에 나타날 수 있다.
Audio Reffered Image Grounding task: MEERKAT이 관심 객체의 bounding box 예측
Audio-Visual Fact-checking: MEERKAT에 대한 text input이 box 좌표를 포함할 수 있음
<Representation of Time Segment>
Natural language expression 내에서 수치 값을 사용해 time interval information을 embedding한다. time interval은 직관적으로 시작 및 종료 지점([start, end])으로 표현되며, 이는 event or activity를 뜻한다. box와 마찬가지로, 이러한 표현은 task에 따라 input or output sequence에 나타날 수 있다.
Image Guided Audio Temporal Localization: model이 query가 발생했을 가능성이 있는 시간 구간을 예측
Audio-Visual Fact-checking: input sequence가 reference time window를 포함할 수 있다.
(지시문 준비 형식에 대한 더 자세한 내용은 Appendix 참고)
MEERKATBENCH: A Unified Benchmark Suite for Fine-grained Audio-Visual Understanding
새로운 audio-visual fine-grained task unification task를 소개한다. 이를 위해 MEEARKATBENCH를 제시하는데 세 가지 fine-grained task와 두 가지 coarse-grained task로 구성된다.
fine1. audio reffered image grounding
fine2. image guided audio temporal localization
fine3. audio-visual fact-checking
coarse1. audio-visual question answering
coarse2. audio-visual captioning
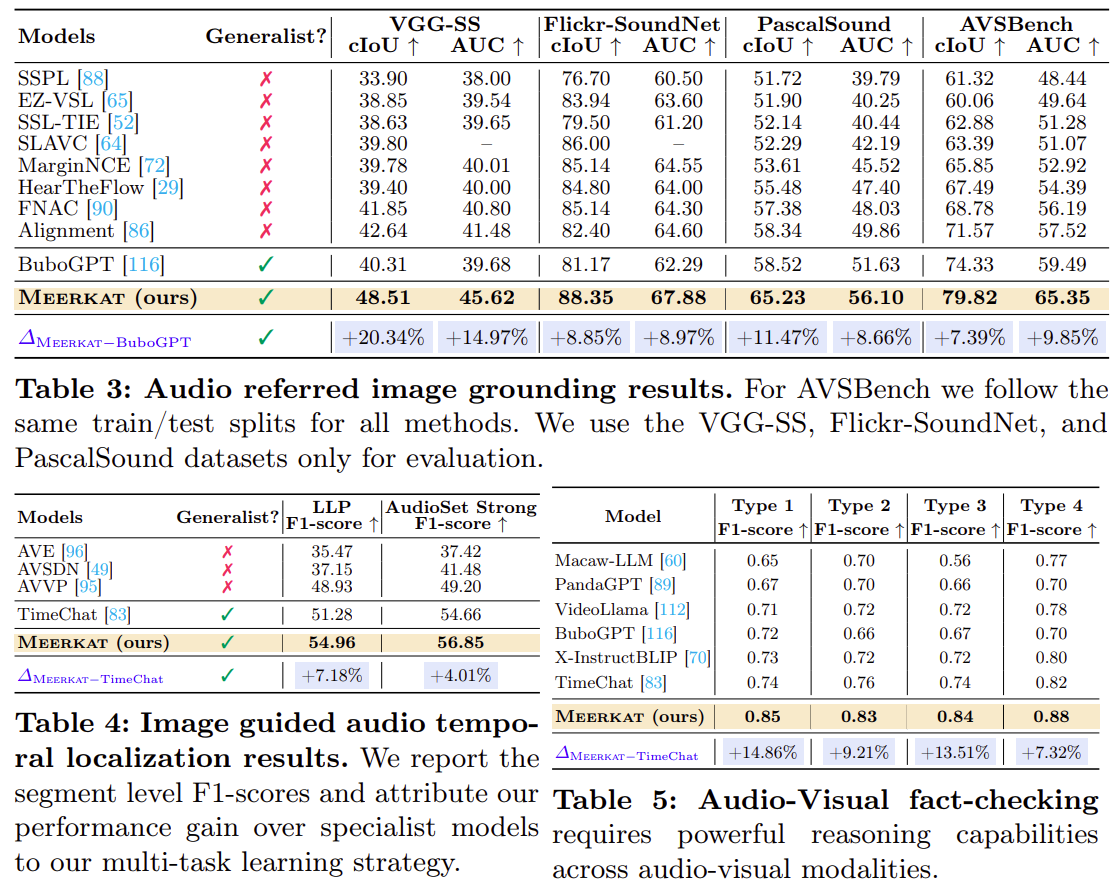
해당 논문을 읽으면서 가장 인상 깊었던? 흥미로웠던 부분은 관심 있는 객체에만 bounding box를 친 후, 이 부분만 cross-attention을 진행한다는 점이다. 그러면 당연히 필요없는 부분도 cross-attention 연산을 하게 될텐데, 그게 아니라 꼭 필요한 부분, 원하는 부분만 attention을 할 수 있으니 너무나도 효율적이라고 생각이 들었다.
'이 부분을 잘 살려서 적용해보면 좋지 않을까' 라는 생각을 했다.