Question Aware Vision Transformer for Multimodal Reasoning (CVPR 2024)
Abstract
Vision-Language models는 multimodal reasoning에서 눈에 띄는 발전을 가능하게 했다. 이러한 architecture는 보통 vision encoder, LLM, visual feature를 LLM's representation space에 정렬시키는(align) projection module로 구성된다.
발전에도 불구하고 critical limitation이 남아있다. ☞ vision encoding 과정이 user query(often in the form of image-related question)와 분리되어 있다는 점이다. 이 결과 생성된 visual features는 image의 query-specific elements에 최적화되어있지 않을 수도 있다.
이를 해결하기 위해 해당 논문은 multimodal reasoning을 위한 Question Aware vision Transformer approach (QA-ViT)를 제안한다. vision encoder 내부에 question awareness를 직접 주입(embed)한다. 이 integration은 제시된 question과 관련된 image 측면에 초점을 맞춘 dynamic visual features를 output한다.
QA-Vi는 model-agnostic이며 어떤 VLM architecture에도 효율적으로 통합될 수 있다.
Introduction

Question-Aware vision encoding의 핵심 idea와 효과를 보여주는 figure.
- Image → ViT → LLM: 일반 VLM 구성. image는 ViT로 feature를 뽑고, 그 결과를 LLM에 넘겨 답을 생성함. 이 때 question은 LLM만 봄
- Imgae → ViT → QA-ViT → LLM: 제안하는 방식. question이 vision쪽(QA-ViT)에도 주입되어, visual feature가 question에 맞게 조정됨 (= quesion-aware encoding)
- 문제점(기존): vision encoder가 question과 분리되어 있어서 vision feature가 question의 keyword(nose, top blue sign..)에 맞춰지지 않음 → 엉뚱한 곳에 주목, 오답
- 해결(제안): QA-ViT로 question을 vision encoding 단계에 직접 반영함. → question 관련 영역에 더 강한 attention → 정확한 예측으로 이어짐
최근 몇 년간 VLM architecture는 중추의 연구 분야로 떠올랐고, Multimodal reasoning 영역에서 상당한 진전을 이끌었다. 이러한 architecture는 근본적으로 visual data와 textual 사이의 간극을 메우는 것을 목표로 한다. model이 visual and textual information 모두를 기반으로 해석하고 이해하며 컨텐츠를 생성할 수 있게 한다. 이러한 modality의 융합은 다양한 task를 가진다.
Multimodal VL achitecture의 핵심에는 vision-language modeling의 개념이 있다. 이러한 model은 일반적으로 세 가지 필수 단계를 포함한다.
1. Unimodal vision architecture가 image에서 meaningful information을 추출한다. 보통 vision encoder는 frozen ViT, often based on CLIP이다.
2. Projection module이 vision과 language 사이의 간극을 메우며, visual features을 language model이 이해하고 처리할 수 있는 feature로 변환한다. 이 module은 보통 simple linear layer or MLP or cross-attention-based transformer achitecture이다.
3. Projected visual information과 textual instruction가 LLM에 삽입되어 task가 완성된다.
이러한 model의 성공은 visual content를 이해할 수 있는 능력뿐 아니라, 동반되는 textual instruction의 관점에서 종종 전체 image 내부의 fine-grained details에 초점을 맞추어 이해할 수 있는 능력에 달려있다. 그러나 기존 architecture는 이 측면에서 최적이 아니며, vision encoding을 주어진 question을 인지하지 못한 채 수행하여, user query에 최적으로 정렬되지 않은 visual feature를 ouput한다.
Vision encoder가 fixed size feature sequence를 output함에 따라, 그 안에 encoding되는 information 수준에는 제한이 있다. 상대적으로 높은 abstraction level때문에 image의 low-level details을 무시하거나 간과할 가능성이 높다. 이러한 문제는 nuanced image understanding가 question에 정확하게 응답하는 데 필수적인 상황에서 특히 문제가 된다. 따라서 vision encoder가 single input function에서 conditional function(조건부 함수)로 전환되어야 한다고 주장한다.
이 limitation을 완화하고 textual conditioned vision encoding을 얻기 위해, multimodal reasoning을 위한 Question Aware Vision Transformer (QA-ViT)를 제안한다. Model이 posed question과 inherent context를 understanding한다면, 올바른 답변에 필수적인 관련 image 측면에 직접 대응하는 visual feature을 추출할 수 있다. Textual prompt가 뚜렷한 spatial location에 대응하도록 vanilla CLIP-based ViT and QA-ViT 모두에 GradCAM을 적용한다. Baseline은 region-specific description으로 prompt되었을 때조차 높은 abstraction level feature을 선호하는 경향이 있는 반면, QA-ViT는 관련 image 부분에 훨씬 더 집중한다.
이 approach는 대부분을 freeze 상태로 유지하여 그 visual understanding 능력을 보존하면서 textual representation을 어떤 vision encoder에도 직접 통합한다. 실제로 ViT에 이미 존재하는 self-attention mechanism이 user query를 나타내는 textual encoding에도 주의를 기울이도로고 활용한다.
QA-ViT의 효과를 입증하기 위해, model-agnostic 성격을 활용하여 BLIP2, InstructBLIP, LLaVA-1.5 등 top-performing system에 통합한다. 추가로 사전학습 없이 정렬되지 않은 VL system을 처음부터 학습할 때의 이점을 보여주기 위해, simple ViT+T5 architecture에도 QA-ViT를 통합한다.
Visual question answering, Image captioning, requiring visual, Optical Character Recogniton(OCR) understanding dataset으로 모든 architecture를 학습시키고 이에 따라 평가한다.
Method

- 처음 input: image + question Q
- Question Encoding
- question Q를 encoding한 뒤 layer별 MLP를 거쳐 vision token과 같은 demension으로 projection
- 이후 vision encoder에 주입할 준비가 된 textual representaion임
- Question Fusing
- Vision encoder의 top-L개 self-attention layer에서 visual token과 question token을 concat하여 frozen self-attention에 통과시킴
- visual token이 question token에 attend하며 보정되고, question-aware한 중간 visual feature를 얻음
- 병렬로 gated projection (head)를 통해 안정적으로 합쳐 최종 question-aware visual feature를 얻음
- Vision Encoder
- 기본 ViT 자체는 frozen 상태를 유지 (원래 능력 보존)
- 상위 layer의 self-attention input만 확장/주입하여 동작
- Projection Module
- question-aware visual feature를 LLM이 이해하는 representation space로 projection
- LLM
- projected question-aware visual feature과 text instruction을 input으로 받아 답변 token 생성
- Output 출력
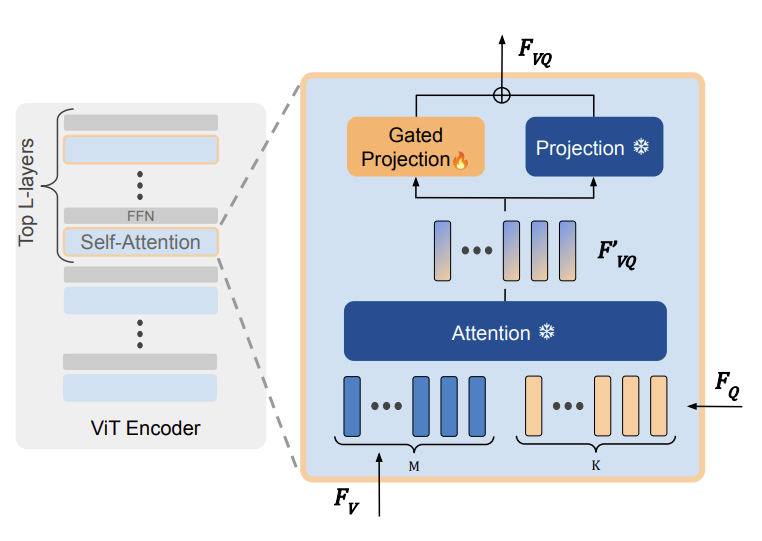
Question token을 ViT의 top-L개 self-attention layer에 주입해 question-aware visual feature를 만드는 과정.
- 왼쪽 회색 박스
- 표준 ViT encoder. 여러 block이 쌓여 있고, 각 block은 self-attention - FFN 순서.
- 제안하는 방법은 top-L layer에만 fusion하는 late fusion
- 오른쪽 파란 박스: top-L layer
- 파란색 tokens: 이전 layer에서 넘어온 visual token M개 (M x C)
- 주황색 tokens: Question Encoding을 거쳐 vision space로 projection된 question token K개 (K x C)
- Attention: frozen self-attention
- Projection: 원래 있던 frozen projection head
- Gated Projection: 새로 추가된 learnable residual projection + tanh
- question-aware visual feature를 얼마나 어떤 방향으로 보정할지 학습
- gating으로 크기 조절
- 학습이 진행되며 β (learnable parameter)가 커지면 해당 경로의 기여도가 증가
- question token을 self-attention input에 붙이면 output이 달라질 위험이 큼
- frozen P(.)가 원래 representation의 안전한 anchor 역할
- Pg(.) tanh( β )가 필요한 만큼한 새로운 정보를 주입해 성능 붕괴를 방지해줌
- Pg(.): residual
- tanh( β ) : gate
- F'VQ: attention을 통과해 question-aware한 중간 visual representation
- FVQ: 최종 question-aware visual feature
- 전체적인 순서
- visual token + question token (concat) → self-attention's input
- frozen self-attention
- visual representation에 대응하는 attention output만 얻음(앞의 M개만 취해 중간 representation)
- projection + gating
Overall Architecture
이 method는 두 가지 근본적인 구성 요소로 이루어진다.
1. Q로 표시되는 question을 Question Encoding module에 입력하며, 이 module은 texual prompt를 처리하고 투영(project)하여, linguistic and visual feature domain간의 간극을 메운다. 이후 textual encoded feature을 Question Fusing module을 통해 frozen vision model 내부에 통합하여 text-aware visual feature를 생성한다. 마지막으로 projection module에 의해 투영되고, instruction embedding과 concat된 후 LLM에 입력되며, LLM이 처리한 후에 전체 system output을 생성한다. 일반적으로 QA-ViT는 오직 vision encoder만 수정하며, architecture의 나머지 부분은 그대로 유지한다.
Question Encoding
natural language prompt를 unimodal vision transformer에 도입하기 위해, 2단계 과정을 제안한다.
1. Question Representation
natural language prompt(question...)를 meaningful representation으로 encoding한다. 기존 LLM의 encoder나 embedding, 또는 designated language model을 사용한다.
2. Representation Projection
MLP를 사용하여 textual representation을 vision model의 feature space로 투영한다. Vision model의 hierarchical structure때문에 서로 다른 layer는 서로 다른 abstraction levels을 가진다. 따라서 더 나은 alignment를 얻기 위해 layer별 MLP를 사용한다.
Question Fusing
Projected textual representation이 주어지면, model-agnostic 방식으로 고정된 ViT architecture에 integrat하기 위해 parameter-efficient fusing mechanism을 제안한다. Vision encoder를 frozen 상태로 유지하는 것은 model의 원래 능력을 온전히 보존하면서 text-conditioned encoding of the image(text로 조건화된 image encoding)를 가능하게 한다.
Fusing Mechanism
Self-attention layer의 input을 visual representation과 projected representations를 concat한 것으로 확장한다. visual 및 question information을 포함하는 K+M 길이의 sequence가 생성된다. frozen self-attention mechanism을 적용하여 textual information에도 주의를 기울이면서 attention score와 output을 생성하여 cross-modal attention을 가능하게 한다. input visual representation에 대응하는 attention output을 선택하여 얻는다.
기존의 fixed projection head와 병렬로 추가적인 projection과 learnable한 gating mechanism을 도입한다. 이 module은 fixed self-attention layer에 question information을 도입함으로써 발생하는 distribution shift를 보상한다(compensate). 이러한 gating의 목적은 residual projection information이 기존 information과 점진적으로 블렌딩되도록 하여 feature의 큰 변형 및 전반적 성능 저하를 피하는 것이다. 이러한 gating은 additional projection layer의 output을 tanh( )와 곱함으로써 수행된다.
Integration Point
Fusing mechanism에서 중요한 것은 textual representations를 vision transformer layers에 통합하는 지점이다. 구체적으로, late fusion을 수행하며, L < N일 때 N-layer ViT의 상위 l개 self-attention layer에서 융합을 적용한다.
lower layer는 주로 low-level visual detail을 포착하고, higher layers는 high-level concept에 초점을 맞춘다. 따라서 fine-grained details를 간과할 가능성은 higher layers에서 나타날 것으로 예상된다.

이 논문도 question-aware concept을 사용했다.
'MovieChat+' 논문은 MovieChat에서는 'encoding 각각 따로 하고, question과 frame간의 similarity를 계산해서 question과 관련된 frame을 집중해서 보자' 이고, 해당 논문은 'encoding부터 question 정보를 함께줘서 question-aware visual feature를 얻은 후에 사용하자' 이다.
둘 다 question-aware한 visual information을 사용할 수 있는 방법이다. 이 두 가지 논문을 읽으면서 question-aware한 정보를 어떻게 얻을 수 있을까에 대한 힌트를 조금은 얻은 것 같다.