Commonsense Video Question Answering through Video-Grounded Entailment Tree Reasoning (CVPR 2025)
Abstract
이 논문은 commonsense video question answering (VQA)를 위한 최초의 video-grounded entailment tree reasoning 방법을 제안한다. VLMs이 주목할 만한 발전을 이루었음에도, video와 그럴듯한 answer 사이의 suprious correlations을 학습하고 있다는 우려가 커지고 있으며, 이는 VLMs의 black-box 특성과 남아있는 benchmarking의 편향에 의해서 강화된다.
이 논문의 방법은 video fragments를 4단계에 걸쳐서 VQA task를 풀어낸다.
- entailment tree construction
- video-language entailment verification
- tree reasoning
- dynamic tree expansion
이 방법의 핵심적인 장점은 전반적인 reasoning types에서 VLMs에 일반화가 가능하다는 점이다.
공정한 평가를 하기 위해서, 해당 논문에서는 LLMs을 기반으로 VQA benchmark answer sets를 재작성하여 model reasoning을 강화하는 de-biasing 절차를 고안한다. 기존 benchmark와 de-biased benchmark에 대한 체계적인 실험을 통해서 benchmark, VLM, reasoning types 전반에 걸쳐서 제안하는 방법의 요소들이 미치는 영향을 나타낸다.
Introduction
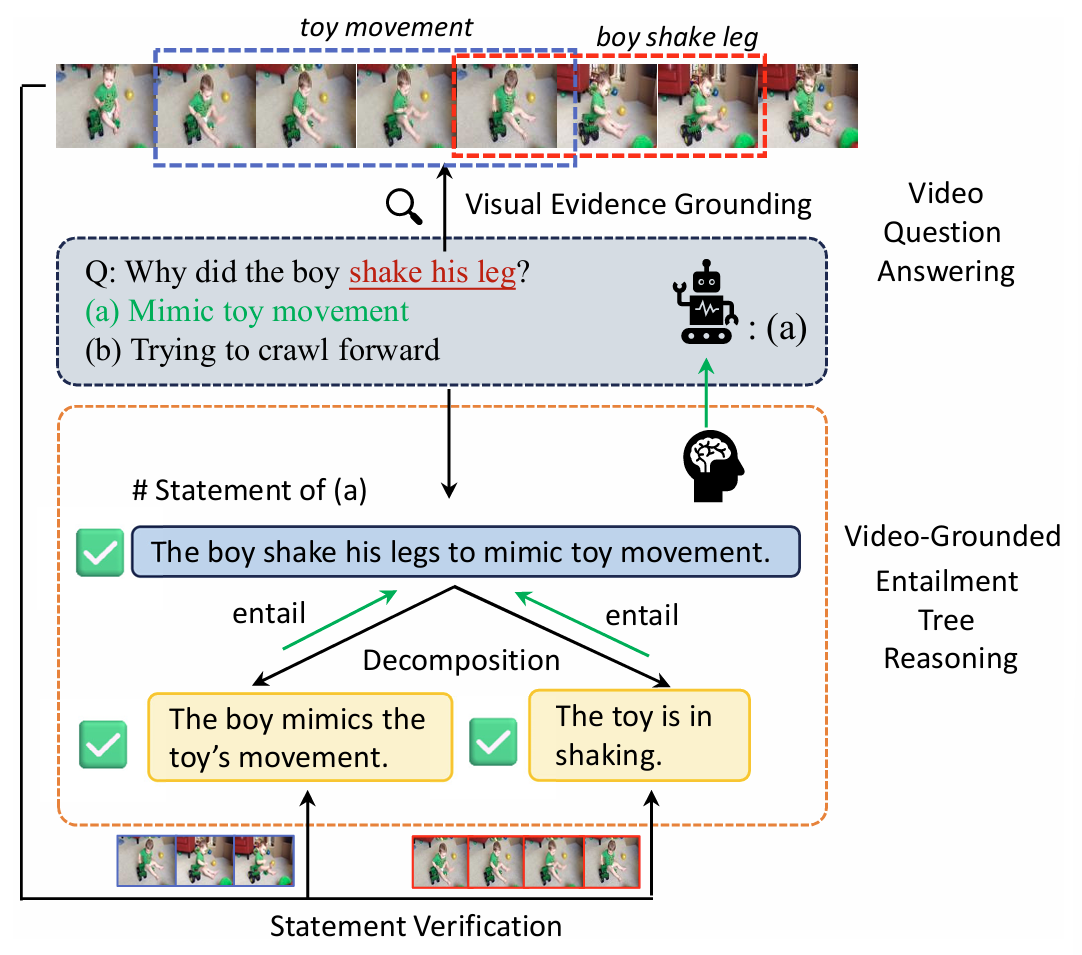
- Input: video + question (multi-choice)
- Visual Evidence Grounding
- '무엇을 봐야 하는지' video에서 찾기
- 검증을 위해 video에서 근거가 되는 frame 구간을 찾아서 alignment
- toy movement → 파란 박스 구간
- boy shake leg → 빨간 박스 구간
- 선택지 → 문장(가설) 변환
- Decomposition: 문장을 더 작은 하위 문장(가설)들로 분해
- Statement Verification: 각 하위 문장을 video로 검증
- 최종 결론: 검증된 추론 사슬로 (a) 선택
본 논문은 commonsense video question answering (VQA)를 위한 video-grounded reasoning 방식을 제안한다. 최근 VQA는 VLMs를 통해 발전을 이루었다. 그러나 이러한 성능 향상이 reasoning에 기반한 것이 아니라, video와 likely answers 사이의 shortcut associations를 학습한 결과라는 우려가 커지고 있다. 이러한 우려는 모델의 black-box적 특성에 의해 더욱 강화되며, 이는 의사 결정 과정의 깊은 이해를 어렵게 만든다.
저자들은 자연어 처리(Natural Language Processing) 분야의 최근 연구에서 영감을 받았다고 한다. 이 분야에서는 함의 트리(entailment trees)가 답변 후보를 명시적으로 분석하기 위한 메커니즘으로 등장하였다. LLMs를 사용하여 하나의 후보를 재귀적으로 가설들(hypotheses)로 분해하고, 자연어 추론 형식을 통해 이러한 가설들을 평가한다. Entailment trees는 모델의 의사 결정 과정을 설명하는 명시적인 reasoning chain(추론 사슬)을 제공하고, 각 단계를 검증할 수 있게 하여 shortcut learning에 대한 우려를 해결했다.
제안하는 방법은 VQA task를 4단계에 걸쳐서 video fragment를 명시적으로 정렬한다.
- entailment tree construction
- video-language entailment verification
- tree reasoning
- dynamic tree expansion
Fig 1과 같이, video와 multiple-choice question이 주어지면 각 정답 후보에 대해 1단계 가설로 작용하는 문장을 생성한다. 각 문장을 반복적으로 분해하여, video에서 신뢰성 있게 검증할 수 있는 하위 문장을 생성하는 것을 목표로 한다. video는 frame 집합으로 구성된 partition들로 분해된다. 각 문장을 검증하는 것은 해당 문장을 video partition에 정렬(grounding)하는 문제로 귀결된다.
이 방법의 핵심적인 장점은 temporal and causal reasoning을 포함한 다양한 reasoning types 전반에 걸쳐서 현재의 video & image 기반 VLMs에 일반화 가능하다는 점이다. Video reasoning 능력을 입증하기 위해, LLMs의 지원을 받아 VQA benchmark가 surprious correlation에 의존하지 않고 video내 reasoning에 적합하도록 보장하는 정답 집합 de-biasing 절차를 개발한다.
실험 결과, video-grounded entailment tree method는 기존 benchmark와 de-biased benchmark 모두에서 video-and image-based baseline을 모두 일관되게 향상시킨다.
Video-grounded entailment tree reasoning & De-biasing commonsense VQA answer sets

(a) Entailment Tree: 정답 후보를 '증명 가능한 문장'으로 만들고, 계속 쪼개는 구조
- Statement(1st level): Q&A → 문장으로 변환
- 선택지를 그대로 쓰지 않고, Statement(1st level)로 바꿈
- Sub-statement(2nd level): 'after' 같은 시간관계를 분해해서 검증 가능한 조각으로 쪼갬
- 가운데 파란 박스 (Fact statement) ☞ (b) 에서 나오는 Fact statement(F)로 연결됨
- 양쪽의 노란 박스 ☞ 각 선택지의 핵심 행동만 남긴 문장
- Sub-statement(3rd level): 더 원자적으로 쪼개서 video로 판단하기 쉽게 만듦
- 빨간 점선 박스들처럼 더 단순한 사건 단위로 쪼갬
- 0.6 ☞ (b)에서 Prover가 산출하는 신념/확률(점수)의 예시
- Sub-statement(4th level): 최소 단위까지 내려가는 경우
- "stop criterion/최대 깊이"까지 가면서 검증 가능한 단위로 최대한 단순화함
(b) Video-language Entailment Verification: 문장 검증을 전체 video가 아니라 필요한 구간에서만 하도록 유도
- Captioner (Cap): video frame → caption(text)로 변환 + 질문의 사실(F) 함께 줌
- video frame이 Captioner로 들어감
- Fact statement(F) ☞ 질문이 가리키는 핵심 사실을 captioner에 조건/힌트로 제공
- 이 결과 Raw captions에 frame 별 설명이 나오고, 이걸 바로 사용하지 않고 다음 단계(semantic parsing)로 감
- semantic parsing 단계에서 '주어-관계-목적어' 같은 구조로 바꿈
- Retrieval (Rtv): Anchor frame 찾기
- Query는 Fact statement에서 나온 구조화 의미를 이용
- Ground (Gnd): 질문이 'after'면 anchor 이후를, 'before'면 anchor 이전을, 아무것도 아니면 주변을 봄
- 정답을 판별할 근거는 전체 영상에 흩어져 있지 않고, 질문이 요구하는 시간관계에 따라 특정 구간에 있을 것
- Prover (Prv): M 구간을 보고 문장(statement)이 참인지 거짓인지 점수로 판단
- Evidence 구간 M을 입력으로 받아 statement의 참/거짓을 평가함
Entailment tree construction
Initial statement generation
질문과 그에 대한 정답 후보들이 주어지면, 먼저 각 question-answer pair를 원래 QA pair의 의미를 유지하는 declarative sentence로 변환한다. 최적의 정답을 선택하는 것은 주어진 video에 대해 올바른 문장을 식별하는 것과 동일하다.
Recursive statement decomposition
문장 집합에 포함된 각 초기 문장에 대해, 해당 문장을 지지하는 증거로서 두 개의 하위 문장을 생성한다.
Statement ⇐ Sub-statement₁, Sub-statement₂
이 문장(Statement)은 두 하위 문장이 모두 참으로 입증될 때에만 참이 되며, 하위 문장들이 상위 문장을 함위한다. 이 절차는 재귀적이며, 하위 문장들은 다시 이를 함의하는 추가적인 하위 문장들로 분해될 수 있다.
함의 트리를 구성하기 위해 최대 깊이에 도달하거나 중단 조건을 만족할 때까지 이러한 하위 문장들을 다음 트리 계층의 새로운 문장으로 재귀적으로 분해한다.
초기 문장 생성과 문장 분해는 LLM prompting을 활용한다. (see implementation details)
Video-language entailment verification
함의 트리가 주어지면, framework는 정렬된(grounded) video content를 증거로 사용하여 문장들을 검증한다. 함의 트리에 포함된 각 문장은 video를 분석함으로써 입증되거나 반박되어야 한다.
Question-aware video captioning
Video가 주어지면, 시각 정보를 상세한 text 정보로 변환한다. Vido frames을 VLM-based captioner에 입력하여 각 frame에 대해 caption을 얻는다. frame을 개별적으로 captioning하면 VQA에 중요한 세부사항을 놓치거나 불필요한 정보를 포함할 수 있다. question이 지시하는 anchor fact를 추출하여 captioner에 사전 지식으로 제공함으로써 관련성 높은 caption 생성을 유도한다. 또한, 각 현재 frame에 대해 이전 모든 frames의 captions을 함께 제공하여 captioner가 과거로부터의 tmporal context를 포착하도록 한다.
Video evidence grounding
Commonsense VQA에서, question이 fact statement를 중심으로 어떻게 추론하느냐에 따라 정답에 필요한 증거는 특정 video 순간들로부터 수집될 수 있다. Temporal reasoning의 경우, 정답은 관련 사실의 시점 이전이나 이후에 발생한 순간들로부터 추론되어야 한다. 이러한 직관에 따라, 답변에 핵심적인 순간들을 국소화하기 위한 two-step evidence-grounding strategy를 설계한다.
- frame 단위 captions이 주어지면, fact statement과 가장 관련성이 높은 key frame을 검색(retrieve)하며 이를 anchor frame이라고 부른다. 단순한 검색 방식은 각 caption을 fact statement와 specific metrics를 사용해 비교하여 anchor frame을 식별하는 것이다. 하지만 해당 논문에서는 structured semantic retrieval strategy를 사용한다.
각 frame과 fact statement의 text 설명을 structured triplets으로 변환한다. triplets은 구조화된 의미를 통해 각 frame 내 객체들의 속성과 관계를 포착한다.
fact statement의 triplets을 query로 사용하여 anchor frame retrieval을 수행하도록 LLM을 prompt한다. LLM은 이후 가장 관련성이 높은 frame ID (timestamp)를 식별하여 반환한다. - question에 내재된 temporal relations를 반영하기 위해, anchor frame을 중심으로 살펴봐야 할 최종 순간을 결정한다. anchor frame을 기반으로, question을 고려하여 "look ahead, look behind, look around" 중 하나를 선택해 탐색을 수행한다.
Visual-text statement prover
grounded visual evidence M이 주어지면, 각 문장이 참인지 거짓인지가 평가된다. 여기서 statement prover(문장 판별기)로 VLM을 사용한다. Prover는 해당 문장에 대한 VLM 내부의 신념(belief)을 탐색함으로써 함의 트리 내 각 문장을 평가한다. 각 문장은 True or False 두 가지 선택지를 갖는 이진 QA task로 변환된다. 이후 이진 QA prompt로 Prover를 직접 질의하고, 단어의 다음 토큰 예측 확률을 사용해 모델의 belief를 도출한다. 두 선택지의 예측 logit을 정규화하여 해당 문장의 신뢰도 점수를 얻는다.
Dynamic entailment tree expansion

지금까지는 사전에 정의된 깊이를 갖는 함의 트리를 구성하기 위해 문장 분해를 재귀적으로 수행하였다. 그러나 모든 문장이 재귀적으로 검증될 필요는 없으며, 특히 VLM에 의해 쉽게 True or False로 판단될 수 있는 문장들이 그러하다. 또한, 깊이가 증가함에 따라 일부 문장들은 원자적이며 직접 검증이 가능하다. 따라서 reasoning 과정의 효율성을 높이기 위해 함의 트리를 동적으로 확장하는 전략을 추가로 채택한다.
각 문장은 prover가 제공하는 두 개의 신뢰도 점수와 연결된다
- The direct score: 문장에 대한 prover model의 belief를 나타낸다.
- The proof score: 문장의 직접적인 하위 문장들의 점수를 곱하여 계산되며, model이 문장을 얼마나 확신을 가지고 증명할 수 있는지를 나타낸다.
문장에 대해, 분해의 목표는 VLM이 문장의 참/거짓을 직접 평가하는 것보다 더 신뢰할 수 있고 설득력 있는 증명 경로를 구축하는 것이다. 동적 트리 확장 과정에서, 분해가 문장의 점수를 향상시키지 못할 경우 해당 분해는 pruning되며, 그 문장 노드는 함의 트리의 리프 노드가 된다. 이 기준은 유익한 분해만을 유지하도록 보장하여, 트리 추론 과정의 효율성을 크게 향상시킨다.
Reasoning over the entailment tree
마지막으로, 함의 트리를 따라 backtrace를 수행하여 각 최상위 문장의 신뢰도 점수를 계산한다. 전체 framework는 최상위 계층에서 가장 높은 점수의 증명을 갖는 문장에 해당하는 정답을 선택한다.
De-biasing commonsense VQA answer sets
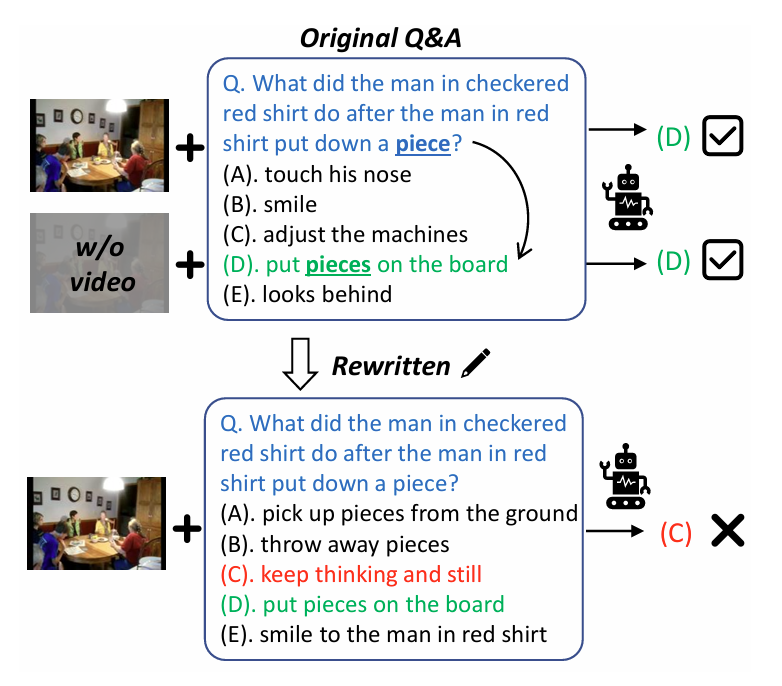

Video-grounded entailmlent trees의 reasoning 능력을 입증하기 위해서는, model의 추론을 강제하는 commonsense VQA benchmark를 사용한 평가가 필수적이다. 최근 연구들은 VQA datasets에 shortcut이 존재하여, VLM이 video 기반 reasoning이 아니라 textual association에 기반해 문제를 해결할 수 있음을 보여주었다. VQA benchmarks이 점점 시간적(after, before) 또는 인과적(how, why, what if) 관계와 같은 commonsense reasoning 능력에 초점을 맞추고 있음에도 불구하고, 이러한 reasoning shortcuts은 평가의 타당성에 영향을 미친다.
이를 위해, 우리는 commonsense VQA 정답 집합에서 reasoning shortcut을 완화하는 de-biasing 절차를 고안한다. 이 절차는 question과 answer는 그대로 유지한 채, 정답 선택지의 오답만을 재작성함으로써 multiple-choice VQA benchmark(e.g., NExT-QA)를 변환한다. LLM(LLaMA-3)을 prompt하여 각 원본 QA 집합에 대해 이 재작성 절차를 수행하도록 한다.
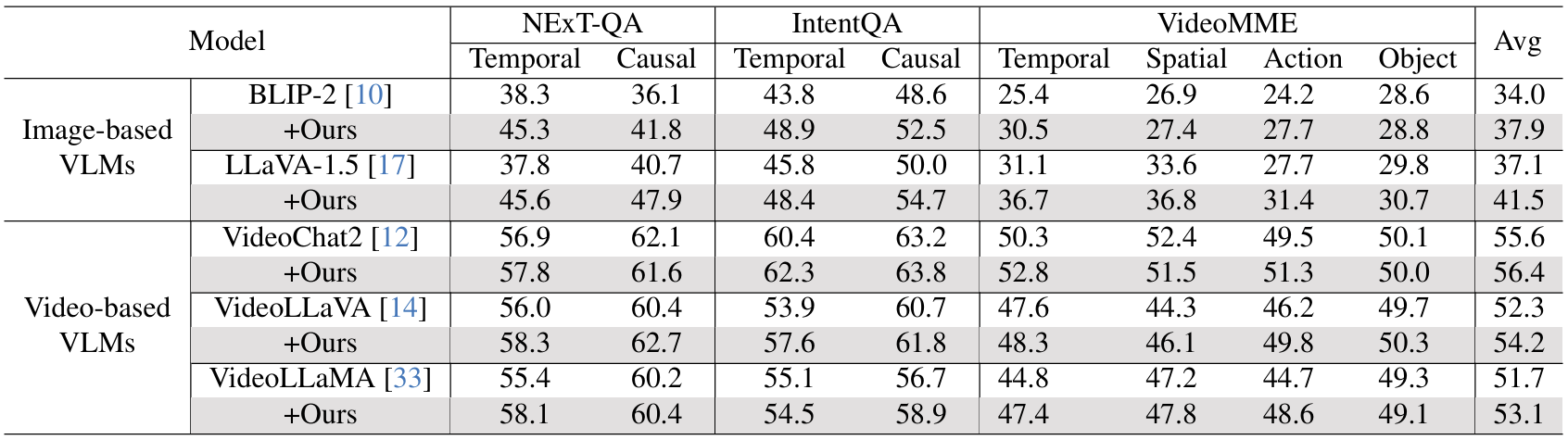



이 논문을 읽고 처음에는, VideoTree의 성능이 더 높은데 굳이 왜 이 방법을 써야하는거지? 라는 생각이 들었다. 그런데 숫자(성능)만이 중요한 게 아니라, 해당 논문은 정말 VQA에서 VLM/LLM을 사용할 때 model이 task의 본질을 이해하고 수행하는 건지를 고려해서 제안한 방법이라는 생각이 들었다. 좀 해석하기 어려운 논문이긴 했지만, VideoQA 논문으로 읽어 보기에는 좋은 것 같다.
'Paper' 카테고리의 다른 글
| Temporal Chain of Thought: Long-Video Understanding by Thinking in Frames (0) | 2026.01.28 |
|---|---|
| Agentic Keyframe Search for Video Question Answering (0) | 2026.01.28 |
| On the Faithfulness of Vision Transformer Explanations (0) | 2025.10.14 |
| Question Aware Vision Transformer for Multimodal Reasoning (2) | 2025.09.24 |
| MovieChat+: Question-aware Sparse Memory for Long Video Question Answering (0) | 2025.09.24 |