MovieChat+: Question-aware Sparse Memory for Long Video Question Answering (TPAMI 2025)
Abstract
최근 video foundation model과 large language model을 통합하여 video understand system을 구축하면 특정 vision task의 limitation을 극복할 수 있다. 하지만 기존 방법들은 complex spatial-temporal module을 사용하거나 video understanding을 위한 visual fearure를 추출하기 위해 추가적인 perception model에 크게 의존하여 short video에서만 좋은 성능을 보인다. Long video의 경우 long-term temporal connection에 수반되는 계산 복잡도와 memory 비용이 크게 증가하여 추가적인 challenge를 야기한다.
해당 논문에서는 Atkinson-Shiffrin memory model의 hierarchical memory structure를 활용하고, 결합된 형태로 Transformer의 token을 carriers of memory로 사용한다. ☞ This paper propose MovieChat within a training-free memory consolidation mechanism to overcom these challenges.
이는 인접한 frame을 시간적으로 병합하여, dense frame from short-term memory를 sparse token in long-term memory로 전환한다. 추가로 trainable module없이 zero-shot approach를 사용하여 pretrained large multi-modal model이 long video를 이해하도록 확장한다.
추가적으로 MovieChat-1K라는 benchmark도 함께 제안하고, long video understanding에서 SOTA를 달성했다.
Introduction
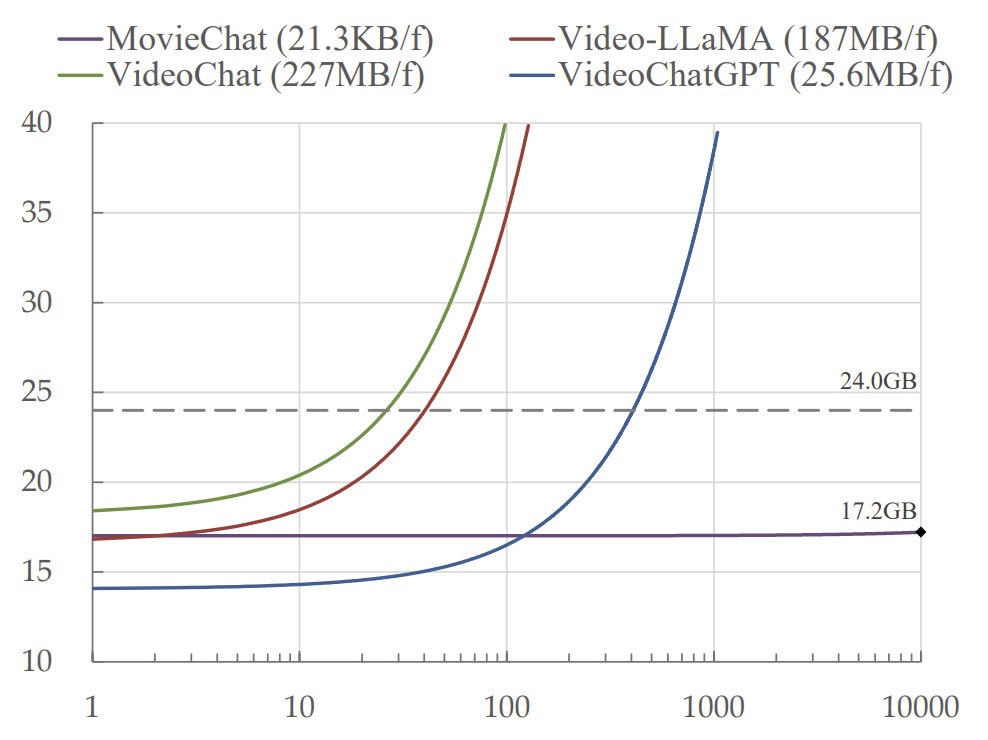
Frame 수(가로 축)가 늘어날 때, VRAM 사용량(세로축)이 어떻게 커지는 지 비교하는 graph
→ MovieChat(this method)에서 frame의 수가 늘어나도 VRAM 사용량이 증가하지 않고 안정적임
LLM에 multi modality를 도입하여 Multimodal Large Language Model(MLLM)로 확장했고, 이를 통해 multimodal 추론과 이해가 가능해졌다. MLLM은 다양한 multimodal task에서 놀라운 능력을 보여줬다. LLM과 다른 task 특화 model에 비해 MLLM은 시나리오에 대해 인간과 유사한 해석, 사용자 친화적 interface, 더 폭넓은 능력을 제공한다.
기존 vision-centric MLLMs은 pre-trained LLM과 visual encoder를 additional trainable module OR simple projection layer를 함께 활용하는 paradigm을 따른다. 이러한 paradigm을 따라 MLLM을 구축한 방법과, 다른 paradigm의 연구들은 video understanding을 위한 visual information을 얻기 위해 complex spatial-temporal modules OR heavily additional perception tools에 크게 의존한다. Long video를 처리할 때, long-term temporal connections에 수반되는 computational complexity & memory cost가 크게 증가하여 추가적인 challenge를 야기한다. 더 나아가, 이러한 system을 평가하기 위해 표준화된 benchmark도 부족하다.
해당 논문의 저자들에 따르면, 이 연구는 long video understanding task (>10K frames)를 처음으로 다룬다. long video understanding에 있어서, computational complexity, memory cost, long-term spatial-temporal connection이 주요 task라고 주장한다. MovieChat는 추가적인 trainable temporal module 없이 zero-shot approach를 사용하여 pre-trained MLLM이 long video understanding하도록 한다.
Atkinson-Shiffrin model은 인간의 기억을 세 단계로 설명한다:
1. 감각 기억(Sensory memory)은 raw input을 잠시 보류
2. 단기 기억(Short-term memory)는 process를 위해 제한된 정보를 관리
3. 장기 기억(Long-term memory)는 광범위하고 영구적인 저장 제공
이러한 hirarchical structure에서 영감을 받아 long video understanding을 위한 memory mechanism을 제안한다.
encoding된 question과의 similarity에 따라 인접한 frame을 시간적으로 결합하여 dense short-term token을 long-term memory token으로 통합(consolidation)한다. 이 mechanism은 빠르게 갱신되는 short-term memory와 더 compact한 long-term memory로 구성된다.
Updated version인 MovieChat+에서 memory의 compactness을 향상시키기 위해 vision-question matching-based memory consolidation mechanism을 설계한다. 이 mechanism은 vision-language model의 예측을 관련 visual content에 유의미하게 anchoring시킨다.
MovieChat+는 VRAM cost 측면에서도 기존 다른 방법들을 뛰어 넘는다.
Contribution
- Pre-trained MLLM을 활용하고, zero-shot/training-free한 memory consolidation mechanism을 활용하여, long video (> 10K frames)를 지원하도록 설계된 최초의 framwork 'MovieChat'를 제안한다.
- Updated version 'MovieChat+'는 training-free vision-question matching-based memory consolidation technique을 사용하여 memory compactness를 향상시켰다.
- 최초의 long video understanding benchmark 'MovieChat-1K'를 공개했다.
MovieChat

Overview
제안하는 방법인 MovieChat은 Frame-wise visual feature extractor, Short-term memory module, Long-term memory module with question-aware consolidation strategy, Video projection layer, Large Language Model (LLM) 등 여러 핵심 구성 요소로 이루어진다. (Fig. 3. 참고)
GPU memory와 RAM에 많은 frame을 동시에 저장해야 하는 문제를 해결하기 위해, sliding window approach를 사용해 video를 효율적으로 처리한다.
두 가지 inference mode - breakpoint mode & global mode를 지원한다.
Breakpoint mode는 video의 특정 순간을 이해하는 데 사용되어 해당 frame이나 장면을 기반으로 answer를 제공한다.
Global mode는 video 전체를 하나로 이해하는 데 사용되어 전반적인 내용과 맥락에 대한 포괄적인 이해를 가능하게 한다.
Visual Feature Extraction
visual feature를 추출하기 위해, video-based foundational models를 사용하는 대신에 simply image-based model을 사용하여 frame-wise features를 token 형태로 얻는다.
ViT-G/14(EVA-CLIP) & BLIP-2의 Q-former를 visual feature extractor로 사용했다. Text와 alignment가 잘 되는 video foundation model이 드물고, 제안한 memory mechanism이 temporal feature를 효과적으로 포착할 수 있기 때문에 사용했다. visual feature는 sliding window 방식으로 추출된다.
Short-term Memory
Short-term memory는 K개의 frame을 fixed-length buffer로 유지하여 frame token을 임시로 저장한다. 추가 처리가 없는 상태에서 sliding window로 G번 추출된 visual features는 short-term memory를 구성하는 데 사용된다.
새로운 batch of visual tokens가 들어오면, short-term memory가 수용량에 도달할 때 현재 저장된 frame을 memory consolidation module로 보내고, short-term memory를 비운다. Memory consolidation module에서 얻는 video feature는 long-term memory를 보강하고, short-term memory re-initialize한다. Re-initialize를 하는 이유는 서로 다른 sliding window에서 정보를 전달하기 위함이다. 이 과정을 거치며 더 효율적인 압축(compression)을 할 수 있다.
Question-aware Long-term Memory (MovieChat+)
Long-term memory는 catastrophic knowledge forgetting 문제를 회피할 수 있고, 이는 long video understanding task를 처리하는 데 중요하다. Short-term memory에 저장된 feature는 dense tokens지만, GPU memory와 computation cost의 한계로 인해 short-term memory에서 나오는 모든 tokens를 long-term memory buffer에 저장하는 것은 불가능하다. 또한, video에서 상당한 temporal redundancy가 관찰된다.
실제로는 전체 long video contents의 일부만이 주어진 question과 관련된다. 이를 위해 updated version인 MovieChat+에서는 특정 question과의 관련성에 기반하여 인접한 frame들을 병합(merge)한다. 이를 통해 video feature representation을 간소화하고 encoding 효율을 향상시킨다. 이 방법은 dense token을 관련 question을 중심으로 sparse memory로 변환하며, 이는 long-term memory에 저장된다.
pre-trained text encoder를 사용하여 특정 question Q를 visual feature과 동일한 embedding 공간으로 encoding한다.
그런 다음 short-term 내 각 frame feature과 encoding된 question 사이의 평균 cosine similarity를 계산한다.
question을 중심으로 video를 볼 때, 대체로 크게 관련 없는 구간은 건너뛴다.
short-term memory의 visual feature가 questino과 매우 관련이 있으면 long-term memory로 더 적게 merge하고, 그렇지 않으면 더 많이 merge한다. 평균 similarity를 threshold와 비교하여 question과의 관련성을 평가한다.
이후, 인접 frame에서 가장 유사한 token을 merge하여 주기적으로 memory consolidation을 수행한다. 여기서 N개의 embedding된 token사이의 평균 cosine similarity를 계산하는데, token은 각 frame의 정보를 효과적으로 요약할 수 있다.
매번 merge 연산 후 M개의 frame을 유지하는 것이 목표이며, 이는 long-term memory에 저장된 풍부한 정보도 함께 embedding한다. merge연산은 각 consolidation 연산에 대해 token 수가 사전 정의된 값 M에 도달할 때까지 반복적으로 수행되며, 그 결과 output video feature을 얻는다.
전체 video의 dense token은 question과의 similarity에 따라 다양한 정도로 compression되어 long-term memory 내에 저장된다.
Inference
이전 방법들은 항상 video 전체의 representation을 사용하여 understanding 및 question-answering을 수행한다. 이러한 방법은 광범위한 overview를 제공하지만, long video에서 특정 순간이나 세부 사항을 정확하게 localizing하는 데 어려움을 겪는다. 이를 위해서 long video understanding task를 위해 global mode와 breakpoint mode 두 가지 inference mode를 제안한다.
<Global mode>
Video 전체에 대한 understanding & question-answering으로 정의된다. 이 mode에서의 초점은 video 전체 length에 걸친 details를 포착하는 데 있다. 따라서 video representation으로 long-term memory만을 사용한다.
<Breakpoint mode>
Video 내의 특정 순간을 understanding하는 것으로 정의된다. Event는 연속성을 가지므로, short-term memory에 저장된 순간과 직접적으로 관련된 정보뿐 아니라 long-term memory에 저장되어 있는, 간접 관련 정보도 고려해야 한다. 따라서 특정 시각에서 질의할 때 video representation은 short-term memory, long-term memory, current video fream feature를 모두 사용한다. 이런 요소들을 단순히 concat하는 것이 뛰어난 결과가 나옴을 관찰했다.
A New Benchmark: MovieChat-1K
Long-form understanding evaluation을 평가하기 위한 new benchmark.
- 규모/구성:
- 1K개 video clip (movie, TV, etc.)
- 14K manual annoataions (question/answer, caption, etc.)
- Update(+): 2K개의 temporal grounding label 추가 (MovieChat+)
- Temporal labels:
- breakpoint mode question에만 부여 (global model는 불필요)
- val/test set에만 annoatation (evaluation용, train용 아님)
- 200개 video에서 2K Q/A pair에 temporal segment(start/end) 표기
- length of segments: 대부분 12s 미만, 평균 6.3s (전체 영상은 약 700s)

Limitation
아칙 초기 단계의 prototype이며 몇 가지 limitation을 가지고 있다.
1. Limited perception capacities: approach 성능은 pre-trained short video understanding model에 의해 제약을 받는다.
2. Inadequate Time Processing: long video 내 evens의 지속 시간 비율에 대한 대략적인 추정만 제공하며, 시간적 세부 사항에서 정밀성이 부족하다.
3. Inefficient Reprocessing for New Questions: 새로운 question이 제기될 때마다 매번 전체 video를 재처리해야 한다.
이 논문은 사실 제목만 보고 'Question-aware' & 'Video Question Answering' 이라는 keyword를 보고 흥미로워서 읽게 되었다. question-aware한 concept을 찾다가 발견했는데... 생각보다 내 기대에는 못 미친 논문인 것 같다. Memory를 short-term이랑 long-term으로 나눈 concept과 question과의 similarity를 계산해서 dynamic하게 chunking한다는 게 흥미로운 point였는데 같은 video에서도 새로운 question이 들어올 때마다 매번 전체 video를 다시 처리 해야한다는 점이 큰 limitation으로 느껴졌다. Long video라면 video의 길이가 길텐데, 매번 재처리를 하면 inference time이 길어질 것 같다. 어쩔 수 없는 문제인가? 싶기도 하다.
그리고 너무 오랜만에 저널 논문을 읽어봐서 그런지.. 컨퍼런스 논문과 확실히 느낌이 다른 것 같다. 컨퍼런스 논문은 아무래도 분량 때문에 실전 압축 내용만 담아놓은 느낌이면, 저널 논문은 좀 더 자세하게 떠먹여 주는? 그런 느낌이다. 대신에 뭔가 저널 논문이 더 복잡한 느낌인 것 같기도 하다.
이 논문에서 내가 가져갈 점은 question-aware를 question과 similarity를 계산해서 video frame을 chunking하는 부분을 dynamic하게 했다는 점이랑 memory를 short/long term으로 나누었다는 점 이렇게 두 가지인 것 같다.