TOGA: Temporally Grounded Open-Ended Video QA with Weak Supervision (ICCV 2025)
들어가기 전에, 'instruction tuning' 의 개념에 대해 알고 있으면 이해하는데 도움이 됩니다!
2025.09.17 - [Concept] - Instruction tuning
Abstract
해당 논문은 video question answering (VideoQA) with temporal grounding 문제를 temporal annotation 없이 weakly supervision으로 해결한 논문이다.
주어진 video와 question에 대해 timestamp([start time, end time])와 question에 대한 answer를 생성한다. 이를 위해서 'TOGA'라는 vision-language model을 제안한다.
Temporal grounding annotation (GT - train)이 없는 weakly supervision 환경에서 동작하며, temporal grounding을 위해서 pseudo labels을 생성하여 사용한다.
answer와 grounding을 동시에 생성하는 것이 QA뿐만 아니라 grounding의 성능도 향상시킨다는 사실을 확인하였다.
이 논문이 지금까지 나왔던 VideoQG의 논문들과는 다르게, multi choice (객관식) 형태가 아니라 open-ended (주관식) 형태의 QA task를 다룬다.
Introduction

input으로 video와 question이 주어졌을 때, 시작과 종료 시간으로 grounding된 open-ended answer를 생성한다. (Fig 1.)
Answer는 free-form sentences로, 단일 단어/구 혹은 선택지 중 하나로 제한되지 않는다.
비용이 많이 드는 temporal annotations에 의존하지 않기 위해 weakly supervised setup이다.
각 video는 여러 개의 question을 포함하고, 이 question들이 겹치는 temporal segment를 가질 수 있기 때문에 각 answer는 고유한 구간에 grounding 되어야 한다. 이 논문에서 다루는 video의 길이는 평균 40초이다. (dataset: NExT-GQA) 이러한 question에 올바른 answer를 생성하기 위해서는 events의 시간적 순서 & 객체 간의 spatio-temporal interaction을 이해해야 한다.
이러한 문제들을 해결하기 위해 TOGA라는 vision-language model (VLM)을 제안한다. TOGA는 video processing framework를 구축하고, 이를 LLM(Large Language Model) 기반의 text processing framework와 결합하여 question을 처리하고 answer를 생성한다. TOGA는 'Answer [start time, end time]' 의 형식으로 answer와 temporal grounding을 공동으로 생성한다.
input으로 video & question이 주어지면, video frame을 sampling하고 pre-trained vision transformer encoder를 사용해 visual feature를 계산한다. question은 LLM tokenizer와 embedding layer로 처리하여 text feature를 추출한다.
Multi-scale vision-language connector (MS-VLC) 를 사용하여 video와 text를 정렬한다(alignment).
MS-VLC는 두 가지 해상도로 video를 처리한다. 낮은 frame rate에서는 저주파 시간 feature를, 높은 frame rate에서는 고주파 시간 feature를 포착한다.
마지막으로, LLM Decoder를 학습하여 text feature과 multi-scale video feature간의 Cross-Attention을 통해서 temporal grounding + answer를 생성한다.
TOGA의 weakly supervision을 위한 다단계 학습 접근법을 제안했다.
1. question-answer annotation과 video description을 활용하여 grounding 없이 answer만 생성하도록 학습
2. 이후 이 model을 사용하여 temporal grounding에 대한 pseudo-labels를 생성한다. 특정 구간을 선택하고, 각 구간에 해당하는 question을 생성한다. 선택된 시간을 포함한 answer는 해당 question에 대한 noise가 포함된 grounding label로 간주된다.
- model은 원래 시간 정보를 학습한 적이 없지만, video를 구간 별로 잘라 질문을 던짐으로써, 그 구간이 해당 답변의 근거라는 것을 pseudo label 형태로 만들어줌
- noisy grounding label? 이 label은 직접적인 정답 label이 아님. model이 만들어낸 답변 + 사용자가 임의로 자른 구간 조합이기 때문에 실제 정답과 완전히 일치하지 않을 수 있다. 따라서 noisy label이라고 표현
3. model을 지시 학습(instruction-tune)하여 temporal reference가 포함된 prompt를 받아들이고, temporal grounding을 포함한 answer를 생성하도록 한다. 이 지시 학습은 model이 question 속 temporal reference를 이해하고, answer 속에 temporal grounding을 포함시킬 수 있는 능력을 확장한다.
- temporal reference (prompt) : What is the activity in?
- temporal grounding : A boy in a red shirt is running
그러나 이러한 pseudo label은 noise가 존재하므로, consistency constraint(일관성 제약)을 부과하여 grounding 성능을 개선한다. 동일한 temporal segment를 참조하는 question과 grounding question에 대한 answer가 일치하는 경우에만 label을 채택한다. 예시는 다음과 같다.
- question : What is the boy in a red shirt doing?
- temporal grounding (GT) : The boy is running
- reference question : What is happening in?
- reference question grounding : A boy in a red shirt is running.
TOGA의 장점
- answer와 grounding을 동시에 생성 - 답변 내용에 맞게 시간 구간 조정 가능
- open-ended answer 생성 - multi choice나 single word에 국한되지 않음
- pseudo label 기반 weak supervision - 외부 model이나 temporal annotation에 의존하지 않음
Contribution
- TOGA 제안
- Weakly supervised setup
- SOTA on benchmarks
Approach

VLM framework는 4가지 주요 module로 구성된다.
- Vision encoder : video로부터 frame 단위 feature 계산
- Large-language text encoder : question으로부터 text feature 계산
- Multi-scale vision-language connector : vision과 text feature를 정렬하여 answer 생성 용이하게 함
- Large-Language text decoder : open-ended answer를 temporal grounding과 함께 생성
4가지 구성 요수 중, vision encoder와 text encoder는 frozen 상태로 유지, MS-VLC와 text decoder만 학습된다.
Vision encoder
주어진 video로부터 frame을 균일하게 sampling하고, 각 frame 단위의 feature를 계산한다.
large-scale vision-lanugage datasets에서 학습된 CLIP vision encoder를 사용한다.
이 encoder는 이미 text-aligned features를 생성하기 때문에 frozen 상태로 둔다.
Text encoder
question은 LLM text encoder로 처리된다. text encoder는 LLM tokenizer와 embedding layer를 결합하여 text feature를 생성한다. 이 feature는 text decoder로 전달된다. 이 모듈도 large and diverse text datasets에서 학습되었기 때문에 frozen 상태로 둔다.
MS-VLC
frame 단위의 feature를 입력으로 받아서 temporal cues(시간적 단서)를 포착하여 temporal grounding된 answer를 생성하도록 한다. question에서 추출된 text feature과 정렬된 video feature를 생성하는 데 학습된다.
- sparse scale : 낮은 frame rate로 sapling (4 frames)
- long term temporal cues 포착
- 긴 구간 grounding에 적합
- dense scale : 높은 frame rate로 sampling (16 frames)
- short term temporal cues 포착
- 짧은 구간 grounding에 적합
각 VLC Block은 RegNet과 3D convolution으로 구현되며, 두 block은 parameter를 공유한다.
Text decoder
LLM text decoder를 학습시켜 multi scale video feature과 token 단위 text feature으로부터 answer를 생성한다. Mistral-7B Instruct를 language decoder로 사용하며, Cross-Attention를 학습하여 답변을 생성한다.
이 방식은 text decoder를 frozen 상태로 answer과 grounding을 별도로 생성하는 기존 접근법과는 달리, 동시에 생성 가능하다.
Multi-stage training
1단계 : Alignment
- MS-VLC module만 학습하여 multi scale video와 text feature를 정렬한다.
- question input을 통해서 정렬된 visual feature를 생성하고, text decoder가 올바른 answer를 만들 수 있도록 한다.
- train data는 video captioning, sentence completion, question answering 등을 포함한 다양한 prompt and response pairs를 구성한다.
2단계 : Instruction tuning
- MS-VLC와 language decoder module을 같이 학습한다. (instruction-tune. for grounding)
- goal : temporal reference가 포함된 prompt를 이해하고, temporal grounding이 포함된 응답을 생성하는 것이다.
- weakly supervised setup이기 때문에 pseudo temporal labels를 생성한다.
- 1단계의 model을 사용하여 video의 temporal segment를 잘라내고, descriptions를 생성한다.
- 이 description과 start/end time을 answer and temporal grounding을 위한 pseudo label로 간주한다.
3단계 : Consistency constraint
- 더 정확한 grounding을 위해, 동일한 temporal segment를 기준으로 question-answer 간의 일관성을 도입한다.
- question과 paired question의 두 응답이 일치하도록 학습하고, 주어진 QA annotation을 바탕으로 정확도를 보장한다.
- self-consistent question-answer와 temporal labels는 answering and grounding 모두의 accuracy를 개선하도록 돕는다.
Prompt design

학습 단계 별로 적합한 promt를 설계한다.
- visual feature를 text token과 함께 포함하기 위해 special token <video>를 정의한다.
- vision-text alignment 단계에서는 multiplt user prompt를 설계한다.
- instruction tuning 단계에서는 temporal reference를 포함한 prompt를 사용하며, model output 형식을 prompt에 명시한다.
- ouput format
- answer : 답변만 생성할 때
- [<start>, <end>] : temporal grounding만 생성할 때
- answer [<start>, <end>] : answer + temporal grounding
- prompt에 output format을 포함시키는 것이 temporal grounding reponse를 생성하는 데 매우 중요하다.
Inference
inference할 때도 동일한 system prompt를 사용하며, response format 지시를 추가한다.
- grounded videoQA : grounding + answering
- open-ended VideoQA (MSVD-QA, ActivityNet-QA) : answering
- 0.6s on A100
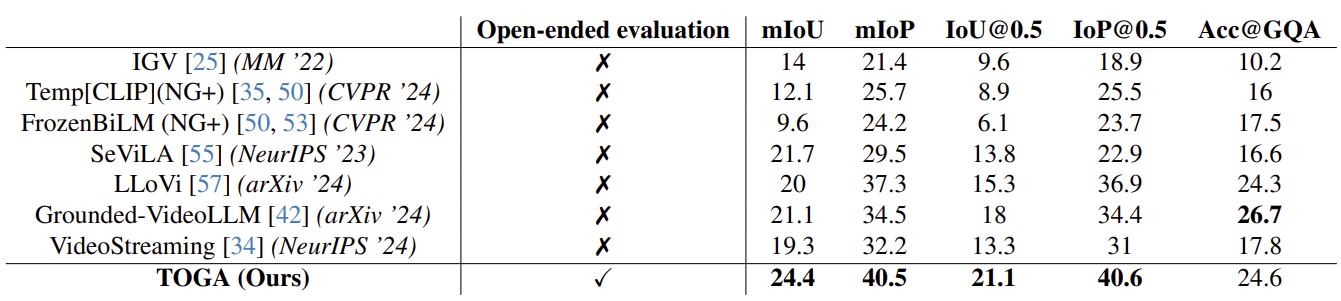
TOGA가 기존 방법들보다 grounding 성능이 우수하게 나왔다. (QA도 우수하게 나옴 - 다른 table에서 확인 가능)
Limitations...
psuedo labels 기반 학습이기 때문에 각 answer에 대해 하나의 temporal segment만 고려한다. 따라서 근거가 여러 구간에 분산된 경우에 처리가 불가하다.
questions를 독립적으로 처리한다. question간 temporal dependency를 활용하지 못한다. NExT-GQA dataset에서 before/after 유형의 question에 답하기 어렵다.
VideoQG(Video Question Grounding)을 공부하면서 concept만 확인하려고 review를 작성해서 부족함이 있을 수 있습니다..