STEP: Enhancing Video-LLMs' Compositional Reasoning by Spatio-Temporal Graph-guided Self-Training (CVPR 2025)
Abstract
Video-LLMs는 최근 basic video understanding(captioning, coarse-grained question answering) task에서 강령한 성능을 보여주었다. 하지만, object relations, interactions, events와 같은 multi-step spatio-temporal inference를 요구하는 compositional reasoning에서는 어렵다.성능을 향상시키는 데에는 extensive manual labor, training data에서 spatio-temporal compositionality 부족, explicit reasoning supervision 부재 등의 문제점이 있다.
해당 논문에서는 Video-LLMs가 raw videos로부터 스스로 학습하는 self-training method의 'STEP'을 제안한다. STEP은 reasoning-rich fine-tuning data를 raw videos로부터 생성하고, 스스로 개선이 가능하다. 다양한 video의 fine-grained, multi-granular한 의미를 포착하기 위해서 'Spatio-Temporal Scene Graph (STSG)' 시공간 장면 그래프 표현을 도입한다.
STSG는 Chain-of-Thought(CoT) 연쇄적 사고 근거를 포함한 multi-step reasoning Question-Answer data를 도출하는데 사용한다. answer와 rationales는 모두 train 목표이고, 이는 explicit reasoning step에 대한 supervision을 통해 model의 추론 능력을 강화하는 것을 목표로 한다.
Introduction

(a) basic task vs challenging compostional task
- model: VideoChat2, VILA
- basic task - 두 model에서 꽤나 높은 성능을 보여줌 (비교적)
- compositional task - 성능이 basic task에 비해서 크게 떨어짐
- 기본적인 QA task에서는 꽤 높은 성능을 보이지만, 합성 추론이 필요한 task에서는 Accuracy가 크게 떨어짐을 보여줌
(b) STEP 적용 전후 성능 향상
- 빨간색 선(VideoChat2) vs 보라색 선(VideoChat2* STEP)
- 빨간색 선: STEP을 적용하지 않은 VideoChat2 성능
- 보라색 선: STEP을 적용한 VideoChat2 성능
- STEP을 적용했을 때 모든 benchmark에서 성능이 향상됨
- STEP이 합성 추론 task에서 특히 큰 성능 향상을 가져온다는 것을 보여줌
(c) compositional task 예시
- VideoChat2* 응답: 잘못된 답변
- VideoChat2*STEP 응답: 추론 과정 설명 후 올바른 답변을 도출함
- STEP은 산순히 마지막으로 본 객체를 답하는 것이 아니라, video의 시간적 흐름과 사건 순서를 따라가며 체계적으로 추론할 수 있게 만든다는 것을 보여줌
Compositional reasoning task에서의 해결되지 않은 문제점
1. Extensive manual labor and lack of generalization. 광범위한 수작업과 일반화 부족
2. Inadequacy of apatio-temporal compositionality. 시공간 합성 부족
- video semantic은 clip-level descriptor에 의해 추출된다.
- 이는 visual interaction과 temporal dynamics를 제한하여 video의 세부적인 spatio-temporal understanding을 방해한다.
- LLM prompt 기반으로 생성된 large-scale datasets은 단순한 question을 만들어내는 경향이 있어, model이 복잡한 문제를 분해하거나 다단계 추론을 학습하는 데 제약이 있다.
3. Absence of explicit supervision for reasoining process. 추론 과정에 대한 명시적 감독의 부재
- 현재 blackbox training method는 model output과 answer 간의 Loss만 계산할 뿐이다.
- model이 중간 추론 단계 대신 spurious correlations에 의존하게 만든다.
- 이런 supervision의 부재는 여러 추론 단계를 일관된 순서로 잘 결합해야 하는 합성 추론 능력을 방해한다.
STEP이라 불리는 새로운 그래프 기반 video self-training method를 제안한다.
SETP은 model이 임의의 raw video로부터 fine-grained and reasoning-rich fine-tuning data를 스스로 생성하여 성능을 향상시키도록 한다.
- 임의의 raw video에서 네 가지 정의된 operations 통해 Spatio-Temporal Scene Graph(STSG)의 symbolic structure induction을 만든다.
- Operation: visual splitting, semantics parsing, dynamic merging, cross-clip bridging
- STSG를 통해 다층적이고 세밀한 video semantic을 포착하고, video의 시공산 세부 정보를 구조적으로 표현할 수 있다.
- Structured STSG representation 위에서 stepwise graph-driven rationale learning을 수행한다.
- multi-step reasoning path를 sapling하여 reasoning-rich Qustion-Answer (QA) task를 생성하고, Chain-of-Thought(CoT) (단계별 연쇄적 사고) 근거를 함께 생성한다.
- 이후 model training에서 answer and rationales를 학습 목표에 포함시켜 복잡하고 다단계적인 합성 추론 능력을 강화한다.
Video-LLMs의 self-training 능력을 활용하여 광범위한 사람 기반 annotation data에 대한 의존도를 크게 줄였다. STSG를 복잡한 video semantic를 포괄하는 통합 구조적 기반으로 사용함으로써, model은 fine-grained spatial relationships and temporal dynamics를 충분히 포착할 수 있다.
Stepwise graph-deiven rationale learning process을 통한 graph structure 내의 reasoning logic을 가져와 sub-question과 근거의 각 단계를 정확하게 정렬할 수 있다.
Contribution
- STEP 제안
- STEP is model-agnostic: 특정 arhitecture에 종속되지 않아 다양한 Video-LLM에 쉽게 적용 가능하며, 최소한의 수작업으로 대규모 raw video data를 효과적으로 train에 사용할 수 있다.
- Improved performance
Method

Step 1: Symbolic Structure Induction
목표: raw video의 복잡한 visual 세부 정보를 구조화된 STSG로 변환
- 1. Visual Splitting
- input: untrimmed video
- PySceneDetec로 장면 전환(scene cut) 탐지 - 여러 clip으로 분할
- 각 clip에서 대표 key frame을 clustering 기반 방법으로 추출 - 불필요한 중복을 줄이고 핵심 의미만 유지
- 2. Semantics Parsing
- 각 key frame마다 Frame Scene Graph (FSG) 생성
- 객체(Static, Dynamic object)와 그 속성(Attribute)을 node로 하고 관계(relation)을 edge로 연결
- ex) human(object) - is holding (relation) - cup(object)
- 이를 통해 frame 단위의 의미를 구조화
- 3. Dynamic Merging
- 연속 frame 간 중복 객체는 하나의 static node로 합쳐서 불필요한 계산 줄임
- 같은 객체의 시간 변화는 motion edge로 연결 (ex. 컵을 들고 있다 - 컵을 내려 놓는다)
- Result: frame 단위 graph(FSGs)가 Temporal Scene Graph (TSG)로 통합됨
- 4. Cross-Clip Bridging
- 서로 다른 clip에 나타난 동일 객체를 연결하는 reference edge 생성
- ex) clip1에서의 '사람'과 clip2에서의 '사람'을 이어줌
- 각 clip에 대한 event edge를 추가해 event 단위 표현 제공
- 최종적으로 통합된 STSG가 생성됨
Step 2: Stepwise Graph-driven Rationale Learning
목표: STSG에서 다단계 추론 경로를 sampling해 QA와 CoT 근거를 생성
- 1. Initial connected node in Q
- question set(Q) & answer set(A)를 설정
- ex) object node(bottle) + attribute node(white)
- q1: What is color of bottle? - a1: White - r1: The color of bottle is white
- 2. Select one node to A
- 이미 사용된 node는 answer set(A)로 이동 - 더 이상 확장 불가
- 3. Expand one node in Q
- New 연결 node를 question에 포함시킴
- ex) man - bottle holding - q2: What is color of the object man is holding?
- a2: White - r2: The man hold a bottle + r1
- 4. Put the expanded node to A
- Q에서 다른 node를 선택해서 계속 확장
- 최대 N번까지 반복 - 다단계 추론 경로 완성
- 5. Add time range by event of clips
- before/after/during 같은 시간적 context를 question에 포함시킴
- 6. LLMs refine the task type and rationable logic
- LLM이 QA 유형을 다양화하고, 논리적 흐름을 보강함
- 다양한 형태의 추론 과제 생성 가능
- Output : <question, rationale, answer>
Step 2: Stepwise Graph-driven Rationale Learning
학습 시 question + answer뿐 아니라, question + rationale도 train objective에 포함시킴
- Loss function
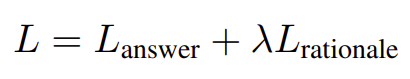
- answer와 rationable을 동일한 비중으로 학습시킴 - 논리적 추론 과정을 단계별로 설명할 수 있는 모델로 학습
STEP은 Video-LLMs가 스스로 추론이 풍부한 train data를 생성하여 성능을 개선할 수 있도록 한다.
주어진 raw video에 대해 먼저 복잡한 visual content를 구조화된 시공간 장면 그래프(STSG) 표현으로 추상화하는 symbolic structure induction을 수행한다. 이어서 STSG 상의 추론 경로를 따라 QA pair와 Chain-of-Thought(CoT) 근거를 도출하는 stepwise graph-driven rationale learning을 구현하여 학습 시 explicit supervision을 제공한다.

기존 Video-LLMs 성능 - Compositional Reasoning Datasets(AGQA, STAR)에서 낮음
STEP을 사용한다면 → 단순 QA뿐만 아니라 Compositional Reasioning task에서도 성능이 향상됨 !
내가 VideoQG에 적용해보고 싶었던 idea와 concept이 유사해서 조금 놀랐던 논문이다.
내가 고민했던 부분을 논리적으로 잘 풀어낸 것 같다.
확실히 결과를 보면, 단순 QA의 성능도 올라가는 것을 봤을 때 기존의 LLM 방식들은 정확하게 question을 이해하고 answering하는 것이 아니라는 것을 다시 한번 느낄 수 있었다. 아마도 spurious correlations 때문이겠지...
...
이 논문을 읽으면서 이 domain(task)에서의 문제점에 대한 생각이 확고해진 것 같다.
- model이 text information에 집중되지 않고, visual information도 잘 사용해야한다.
- model이 visual information을 어떻게 잘 사용할 수 있을 지 guide를 잘 해줘야한다.
- 사람이 visual information에서 얻을 수 있는 정보보다 model이 얻는 정보는 훨씬 적은 것 같다. (너무 단편적임)
- model이 최대한 visual information에서 뽑을 수 있는 정보를 다 사용하면 좋겠다. (진짜 풍부하고 많은 정보를)
- model이 visual information에서 충분한(많은) 정보를 뽑아내지 못한다면?? → → 뽑아내서 전달해주자 ! ! !
이제 앞으로 이것들을 어떻게 해결할 수 있을까 생각을 해보도록 하겠슴니다. . .